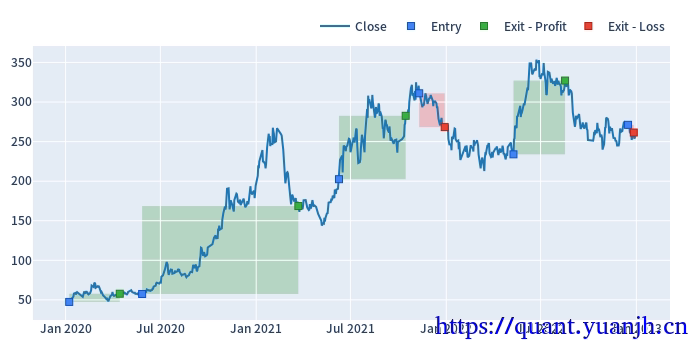
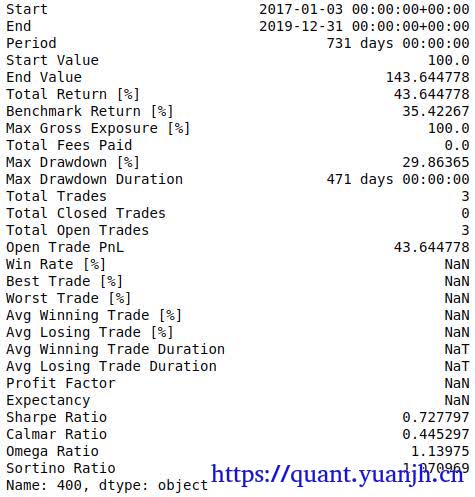
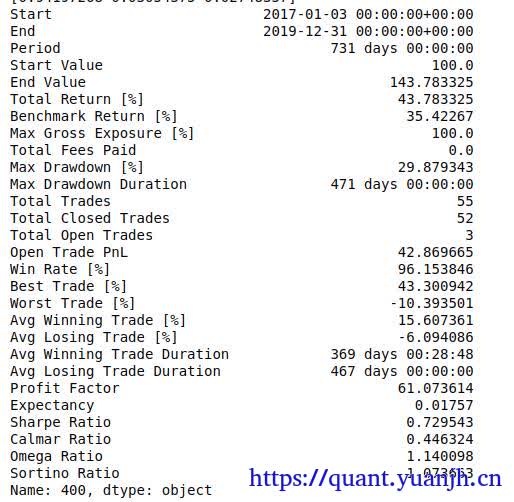
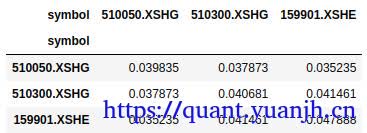
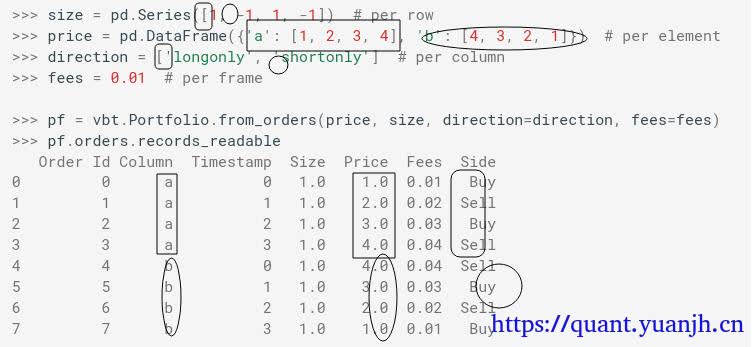
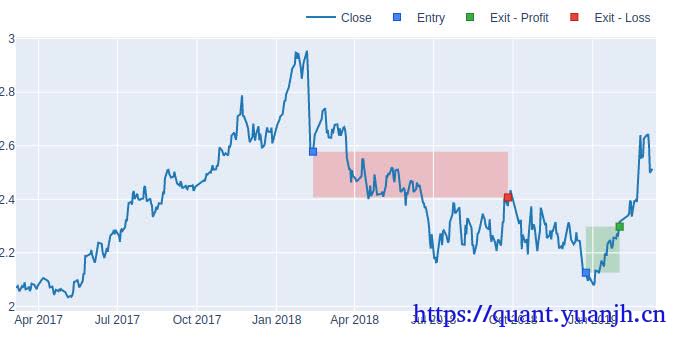
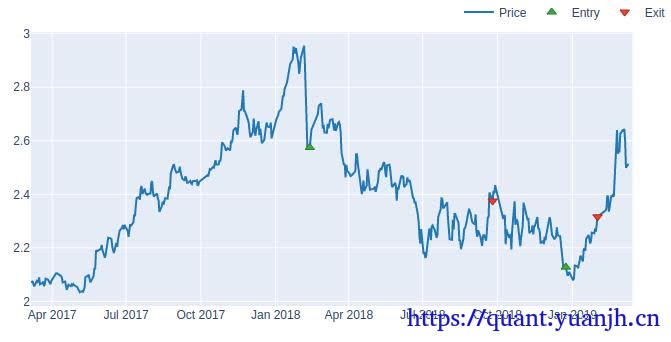
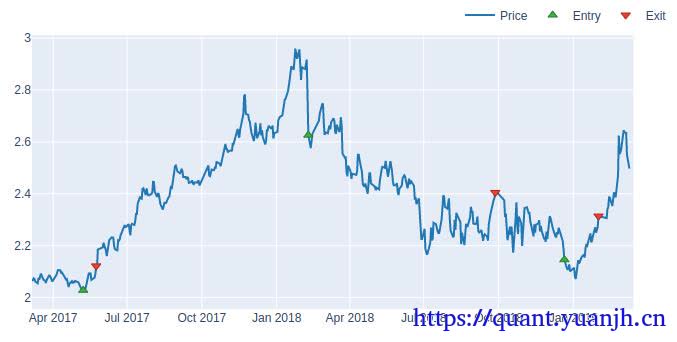
本文在上一篇文章(05dma_03rollingGridParamV2)面临问题
对于双均线,最终采用参数为(20,22),(30,35)这样的参数组合,显然不合理,有对行情进行拟合的嫌疑。
较合理的参数组合方式是,采用快线以及慢线相对快线的倍率。大致认为剔除二者相关性了(正交性)。
此时就无法借助run_combs创建组合计算指标了,需基于vbt创建新技术指标DualMA。
勘误:此篇文章部分截图可能有误,此文章的后继文章“DMA之六滑窗网格参数优选”修复此问题。请查阅后文。
01,基础配置信息
1 | #conda envs:vectorbt_env |
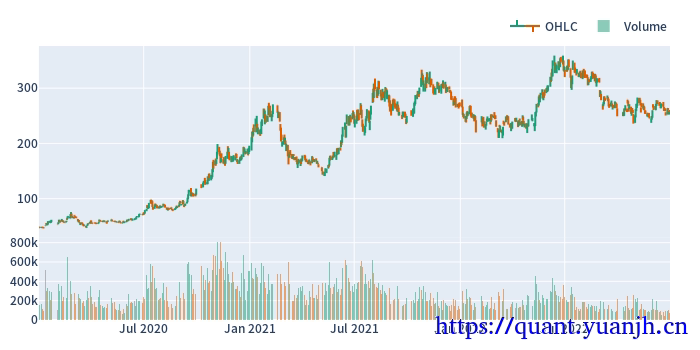
02,行情获取和可视化
a,时间交易参数配置
1 | # Enter your parameters here |
b,获取行情和行情mask
1 | # Download data with time buffer |
ohlcv_wbuf.shape: (978, 5)
ohlcv_wbuf.columns: Index(['Open', 'High', 'Low', 'Close', 'Volume'], dtype='object')
ohlcv.shape: (728, 5)
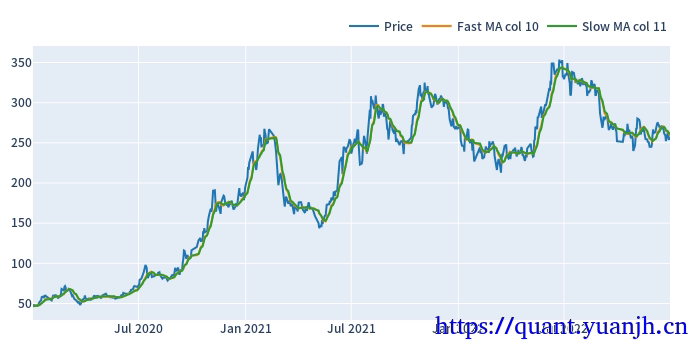
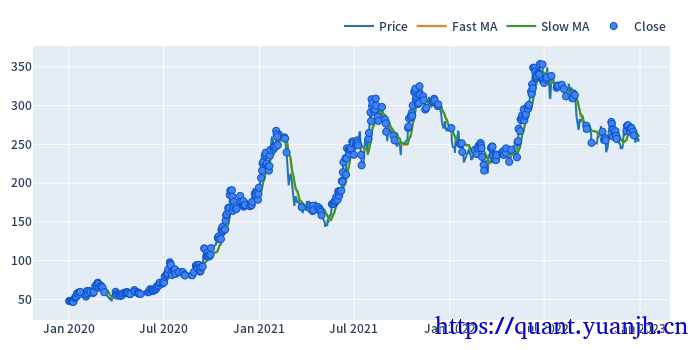
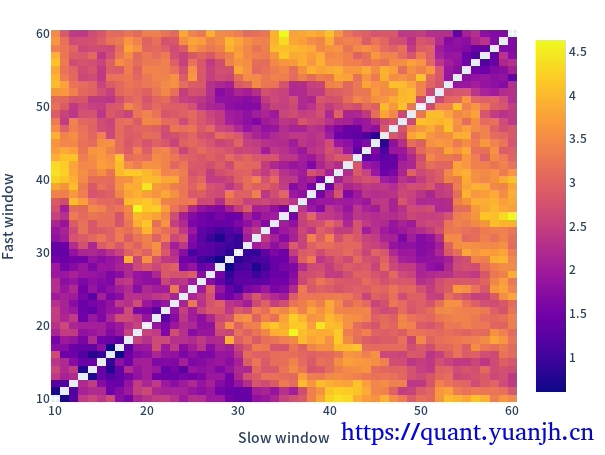
20,网格参数-指标计算和可视化
仅可视化第一列
1 | fast_windows = np.arange(10, 50,5) |
fast_windows: [10 15 20 25 30 35 40 45]
slow_multis: [1.5 2. 2.5 3. 3.5 4. 4.5 5. ]
dualma.fast_ma.head(3)
dualma_fast_window 10 15 20 25 30 35 40 45
dualma_slow_multi 1.5 2.0 2.5 3.0 3.5 4.0 4.5 5.0 1.5 2.0 2.5 3.0 3.5 4.0 4.5 5.0 1.5 2.0 2.5 3.0 3.5 4.0 4.5 5.0 1.5 2.0 2.5 3.0 3.5 4.0 4.5 5.0 1.5 2.0 2.5 3.0 3.5 4.0 4.5 5.0 1.5 2.0 2.5 3.0 3.5 4.0 4.5 5.0 1.5 2.0 2.5 3.0 3.5 4.0 4.5 5.0 1.5 2.0 2.5 3.0 3.5 4.0 4.5 5.0
date
2020-01-02 00:00:00+00:00 46.665 46.665 46.665 46.665 46.665 46.665 46.665 46.665 45.824667 45.824667 45.824667 45.824667 45.824667 45.824667 45.824667 45.824667 45.3025 45.3025 45.3025 45.3025 45.3025 45.3025 45.3025 45.3025 44.9476 44.9476 44.9476 44.9476 44.9476 44.9476 44.9476 44.9476 44.816667 44.816667 44.816667 44.816667 44.816667 44.816667 44.816667 44.816667 44.594571 44.594571 44.594571 44.594571 44.594571 44.594571 44.594571 44.594571 44.5425 44.5425 44.5425 44.5425 44.5425 44.5425 44.5425 44.5425 44.440222 44.440222 44.440222 44.440222 44.440222 44.440222 44.440222 44.440222
2020-01-03 00:00:00+00:00 46.972 46.972 46.972 46.972 46.972 46.972 46.972 46.972 46.128667 46.128667 46.128667 46.128667 46.128667 46.128667 46.128667 46.128667 45.5025 45.5025 45.5025 45.5025 45.5025 45.5025 45.5025 45.5025 45.1420 45.1420 45.1420 45.1420 45.1420 45.1420 45.1420 45.1420 44.964000 44.964000 44.964000 44.964000 44.964000 44.964000 44.964000 44.964000 44.723714 44.723714 44.723714 44.723714 44.723714 44.723714 44.723714 44.723714 44.6265 44.6265 44.6265 44.6265 44.6265 44.6265 44.6265 44.6265 44.555556 44.555556 44.555556 44.555556 44.555556 44.555556 44.555556 44.555556
2020-01-06 00:00:00+00:00 47.138 47.138 47.138 47.138 47.138 47.138 47.138 47.138 46.456000 46.456000 46.456000 46.456000 46.456000 46.456000 46.456000 46.456000 45.7310 45.7310 45.7310 45.7310 45.7310 45.7310 45.7310 45.7310 45.3376 45.3376 45.3376 45.3376 45.3376 45.3376 45.3376 45.3376 45.112667 45.112667 45.112667 45.112667 45.112667 45.112667 45.112667 45.112667 44.871143 44.871143 44.871143 44.871143 44.871143 44.871143 44.871143 44.871143 44.7115 44.7115 44.7115 44.7115 44.7115 44.7115 44.7115 44.7115 44.660222 44.660222 44.660222 44.660222 44.660222 44.660222 44.660222 44.660222
dualma.slow_ma.head(3)
dualma_fast_window 10 15 20 25 30 35 40 45
dualma_slow_multi 1.5 2.0 2.5 3.0 3.5 4.0 4.5 5.0 1.5 2.0 2.5 3.0 3.5 4.0 4.5 5.0 1.5 2.0 2.5 3.0 3.5 4.0 4.5 5.0 1.5 2.0 2.5 3.0 3.5 4.0 4.5 5.0 1.5 2.0 2.5 3.0 3.5 4.0 4.5 5.0 1.5 2.0 2.5 3.0 3.5 4.0 4.5 5.0 1.5 2.0 2.5 3.0 3.5 4.0 4.5 5.0 1.5 2.0 2.5 3.0 3.5 4.0 4.5 5.0
date
2020-01-02 00:00:00+00:00 45.824667 45.3025 44.9476 44.816667 44.594571 44.5425 44.440222 44.6384 45.180455 44.816667 44.545676 44.440222 44.717692 45.135167 45.513134 46.025200 44.816667 44.5425 44.6384 45.135167 45.697429 46.307750 46.683111 47.0983 44.545676 44.6384 45.235806 46.025200 46.560460 47.0983 47.997679 48.61136 44.440222 45.135167 46.025200 46.683111 47.425238 48.410917 48.769630 48.8484 44.717692 45.697429 46.560460 47.425238 48.496066 48.803714 48.852357 49.430914 45.135167 46.307750 47.0983 48.410917 48.803714 48.892313 49.622778 50.14240 45.513134 46.683111 47.997679 48.769630 48.852357 49.622778 50.162574 50.375822
2020-01-03 00:00:00+00:00 46.128667 45.5025 45.1420 44.964000 44.723714 44.6265 44.555556 44.6660 45.373636 44.964000 44.652162 44.555556 44.741538 45.119167 45.485821 45.984267 44.964000 44.6265 44.6660 45.119167 45.666714 46.291125 46.643333 47.0707 44.652162 44.6660 45.229677 45.984267 46.549080 47.0707 47.936429 48.56848 44.555556 45.119167 45.984267 46.643333 47.349905 48.362083 48.758074 48.8320 44.741538 45.666714 46.549080 47.349905 48.460984 48.784357 48.838471 49.366457 45.119167 46.291125 47.0707 48.362083 48.784357 48.878875 49.584500 50.12260 45.485821 46.643333 47.936429 48.758074 48.838471 49.584500 50.141139 50.379778
2020-01-06 00:00:00+00:00 46.456000 45.7310 45.3376 45.112667 44.871143 44.7115 44.660222 44.6908 45.562273 45.112667 44.787297 44.660222 44.773846 45.116667 45.474478 45.950800 45.112667 44.7115 44.6908 45.116667 45.641143 46.267875 46.621889 47.0449 44.787297 44.6908 45.232742 45.950800 46.534598 47.0449 47.864554 48.52880 44.660222 45.116667 45.950800 46.621889 47.278952 48.320667 48.743185 48.8232 44.773846 45.641143 46.534598 47.278952 48.406803 48.770500 48.833885 49.298743 45.116667 46.267875 47.0449 48.320667 48.770500 48.860063 49.552222 50.09115 45.474478 46.621889 47.864554 48.743185 48.833885 49.552222 50.122772 50.388044
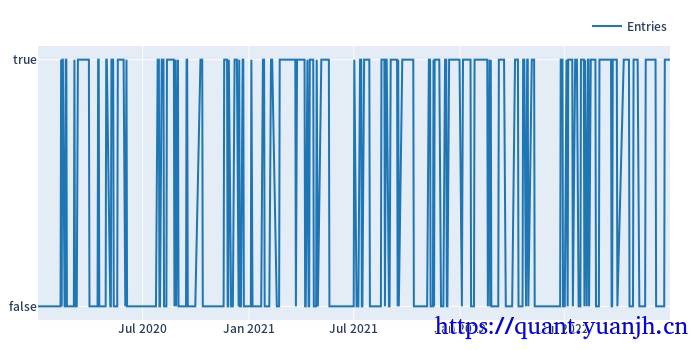
21,网格参数-信号计算和可视化
仅可视化第一列
dmac_size.shape: (728, 64)
dmac_size.iloc[:3,:3]:
dualma_fast_window 10
dualma_slow_multi 1.5 2.0 2.5
date
2020-01-02 00:00:00+00:00 True True True
2020-01-03 00:00:00+00:00 True True True
2020-01-06 00:00:00+00:00 True True True
Start 2020-01-02 00:00:00+00:00
End 2022-12-30 00:00:00+00:00
Period 728
Total 474.03125
Rate [%] 65.114183
First Index 2020-01-15 16:52:30+00:00
Last Index 2022-11-07 20:15:00+00:00
Norm Avg Index [-1, 1] -0.159967
Distance: Min 1.0
Distance: Max 82.734375
Distance: Mean 1.464916
Distance: Std 5.175417
Total Partitions 6.671875
Partition Rate [%] 1.510978
Partition Length: Min 41.671875
Partition Length: Max 211.171875
Partition Length: Mean 110.468174
Partition Length: Std 78.523847
Partition Distance: Min 26.78125
Partition Distance: Max 82.734375
Partition Distance: Mean 51.365493
Partition Distance: Std 28.015768
Name: agg_func_mean, dtype: object
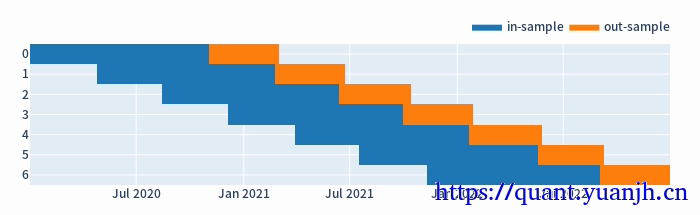
22,行情,信号的滑窗处理
注意点:
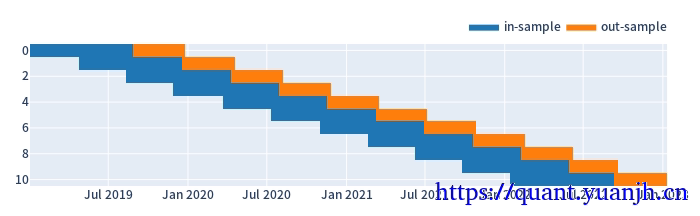
01,训练集和验证集比例3:1,或者2:1,对应:window_len和set_lens为4:1(或3:1),过大了历史包袱沉重,无法及时响应最新行情,过小了则容易参数跳变,形成类似过拟合效果
a,参数设置和效果预览
代码中
1 | #todo 这里是自然日计算的,但后面训练,验证集个数计算都完全正确,哪里应该和预想的不一致 |
1 | # 滚动周期参数设置和大致效果可视化 |
split_kwargs: {'n': 11, 'window_len': 240, 'set_lens': (80,), 'left_to_right': False}
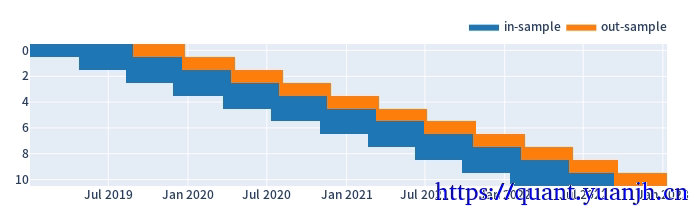
b,根据滑窗参数切分行情数据和信号
in_price.shape: (160, 11)
out_price.shape: (80, 11)
in_price.index: RangeIndex(start=0, stop=160, step=1)
in_price.columns: Int64Index([0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10], dtype='int64', name='split_idx')
in_price[0:3]:
split_idx 0 1 2 3 4 5 6 7 8 9 10
0 49.17 58.15 51.20 43.39 48.15 97.90 167.98 239.52 202.00 251.77 253.14
1 48.06 56.16 49.50 43.15 49.73 96.55 164.08 225.00 214.11 252.50 266.49
2 50.65 55.36 50.29 43.79 52.25 94.50 168.03 208.99 227.02 246.86 266.08
###############################
in_dmac_size.shape: (160, 704)
out_dmac_size.shape: (80, 704)
in_dmac_size.iloc[:5,:5]:
split_idx 0
dualma_fast_window 10
dualma_slow_multi 1.5 2.0 2.5 3.0 3.5
0 True True True True True
1 True True True True True
2 True True True True True
3 True True True True True
4 True True True True True
23,滑窗的收益数据计算
a,持有参数收益
在此区间,基础标的物表现
1 |
|
split_idx
0 0.235446
1 -1.630616
2 0.598889
3 2.647397
4 4.501923
Name: sharpe_ratio, dtype: float64
split_idx
0 -0.929956
1 2.065991
2 4.100300
3 4.801291
4 0.688785
Name: sharpe_ratio, dtype: float64
b,网格参数收益(训练集和验证集)
in_sharpe.shape: (704,)
dualma_fast_window dualma_slow_multi split_idx
10 1.5 0 0.235446
2.0 0 0.235446
2.5 0 0.235446
3.0 0 0.235446
3.5 0 0.235446
...
45 3.0 10 0.663486
3.5 10 0.663486
4.0 10 0.663486
4.5 10 0.663486
5.0 10 0.663486
Name: sharpe_ratio, Length: 704, dtype: float64
out_sharpe.shape: (704,)
dualma_fast_window dualma_slow_multi split_idx
10 1.5 0 -0.929956
2.0 0 -0.820595
2.5 0 -0.820595
3.0 0 -0.820595
3.5 0 -0.820595
...
45 3.0 10 -0.554763
3.5 10 -0.554763
4.0 10 -0.554763
4.5 10 -0.554763
5.0 10 -0.554763
Name: sharpe_ratio, Length: 704, dtype: float64
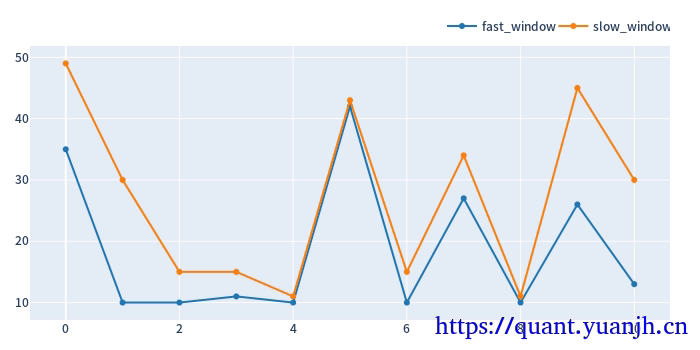
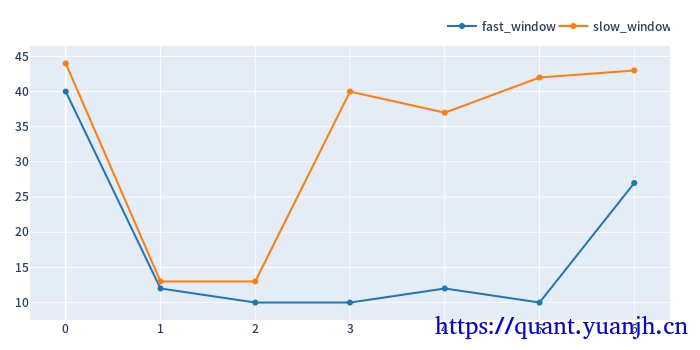
c,训练集上的最佳参数用于验证集
大致思路:
01,获取各split_idx的最佳收益(sharp_radio)的参数组合idxmax,也就是fast_window,slow_window,split_idx,三维索引元组
02,按照split_idx进行聚类,取得各split_idx对应的最佳参数。实际含义就是各滑动窗口的最佳参数
1 | def get_best_index(performance, higher_better=True): |
in_best_index[:5]
MultiIndex([(40, 5.0, 0),
(10, 3.0, 1),
(10, 1.5, 2),
(10, 1.5, 3),
(10, 1.5, 4)],
names=['dualma_fast_window', 'dualma_slow_multi', 'split_idx'])
in_best_window_pairs[:5][:]:
[[ 40. 200.]
[ 10. 30.]
[ 10. 15.]
[ 10. 15.]
[ 10. 15.]]
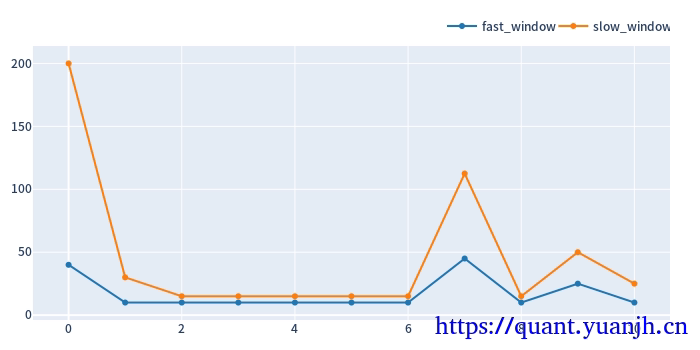
将滚动获取的最佳参数用于验证集,统计收益信息
in_best_index.shape: (11,)
in_best_index:
MultiIndex([(40, 5.0, 0),
(10, 3.0, 1),
(10, 1.5, 2),
(10, 1.5, 3),
(10, 1.5, 4),
(10, 1.5, 5),
(10, 1.5, 6),
(45, 2.5, 7),
(10, 1.5, 8),
(25, 2.0, 9),
(10, 2.5, 10)],
names=['dualma_fast_window', 'dualma_slow_multi', 'split_idx'])
out_dmac_size.shape: (80, 704)
out_dmac_size_reindexed[in_best_index].shape: (80, 11)
dmac_pf_out.trades.records[:5]
id col size entry_idx entry_price entry_fees exit_idx exit_price exit_fees pnl return direction status parent_id
0 0 0 199.762836 0 49.934525 24.937656 79 46.85 0.0 -641.111119 -0.064271 0 0 0
1 1 1 222.599259 0 44.811750 24.937656 79 58.80 0.0 3088.836429 0.309656 0 0 1
2 2 2 182.338041 0 54.706425 24.937656 79 88.73 0.0 6178.854345 0.619430 0 0 2
3 3 3 114.462060 0 87.147325 24.937656 79 183.53 0.0 11007.221874 1.103474 0 0 3
4 4 4 59.581957 0 167.417500 24.937656 79 176.88 0.0 538.856616 0.054020 0 0 4
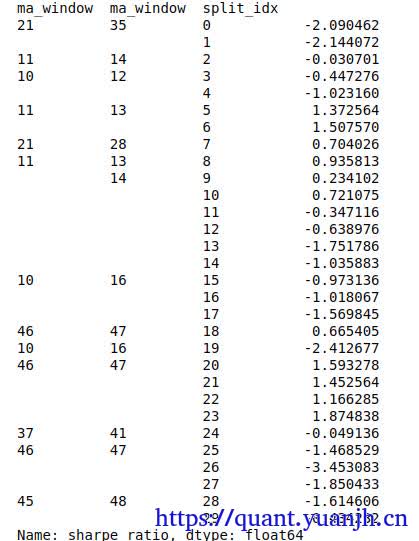
out_test_sharpe.head(5)
dualma_fast_window dualma_slow_multi split_idx
40 5.0 0 -0.929956
10 3.0 1 2.065991
1.5 2 4.100300
3 4.801291
4 0.688785
Name: sharpe_ratio, dtype: float64
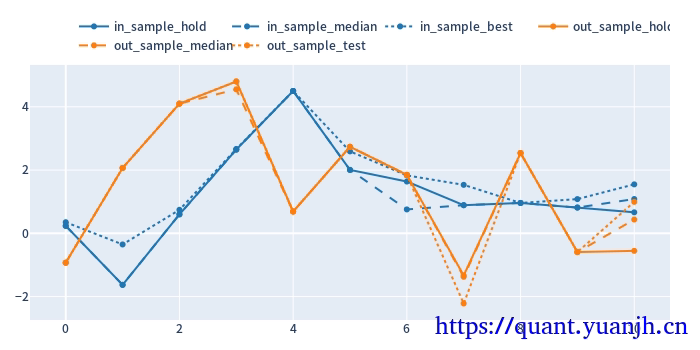
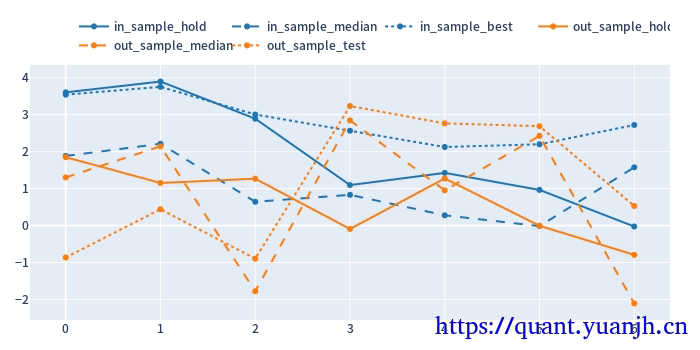
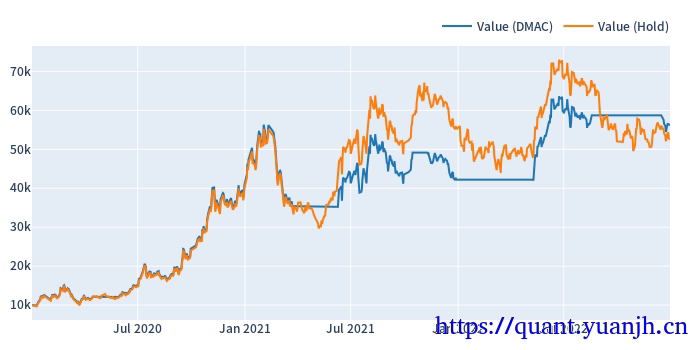
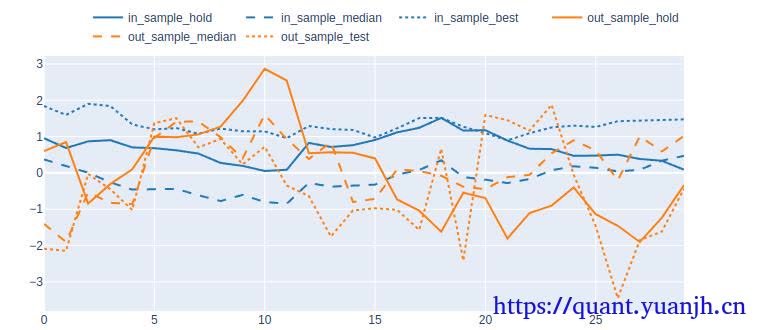
24,sharp ratio的汇总可视化
1 | cv_results_df = pd.DataFrame({ |
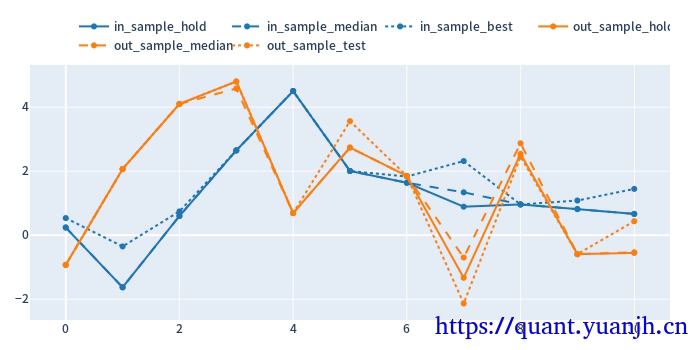
关注点:
蓝色部分
正常排序是(从上到下):点线,实现,线段,
橘色部分
实线对实线
说明测试集和验证集的周期收益情况,二者同时出现0轴同侧较好(同时上涨,同时下跌,保持行情的稳定性or延续性)
线段对线段
二者一方面随着各自颜色的实线趋势变化(受各自实线影响较大),其他应该无必然联系
点线对点线
蓝色点高于橘色点线,蓝色是训练集内最佳,橘色则是训练集得到最优参数用于验证集结果收益,大概率低于验证集。
测试,验证集时间长度差异,引入偏差
由于测试集一般是验证集的2-3倍(或更多),对于单边行情(假如上涨),则(测试集的)实线收益。蓝色线大概率位于橘色线上方。
如果下跌,则相反。蓝色由于时间长,大概率位于橘色下方。
注意:
01,202406,对于当前case,y周取值为sharp ratio夏普比,而非收益率。所以数据点高低并不反映收益率。
所以,以上结论需要稍斟酌,并不完全准确。
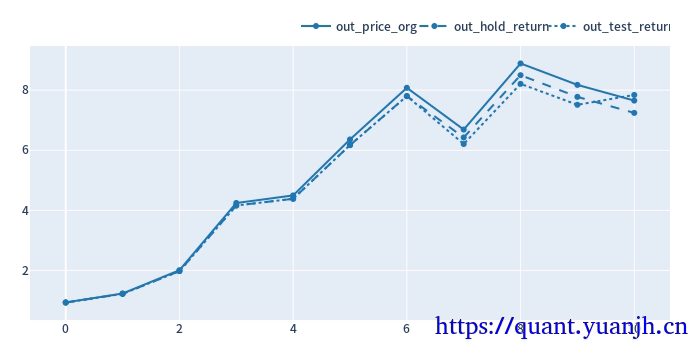
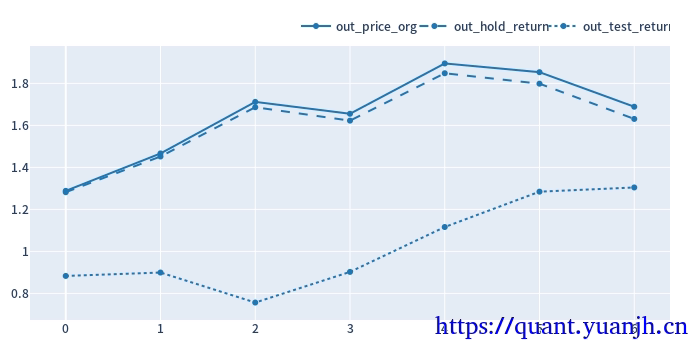
25,滚动回测收益可视化
1 | # 验证集:原始价格变动 |
out_price_org shape: (11,)
out_price_org.head(5)
split_idx
0 0.940574
1 1.315436
2 1.625985
3 2.111239
4 1.059162
dtype: float64
out_hold_return shape: (11,)
out_hold_return.head(5) + 1
split_idx
0 0.935889
1 1.308884
2 1.617885
3 2.100722
4 1.053886
Name: total_return, dtype: float64
out_test_return shape: (11,)
out_test_return.head(5) + 1
dualma_fast_window dualma_slow_multi split_idx
40 5.0 0 0.935889
10 3.0 1 1.308884
1.5 2 1.617885
3 2.100722
4 1.053886
Name: total_return, dtype: float64
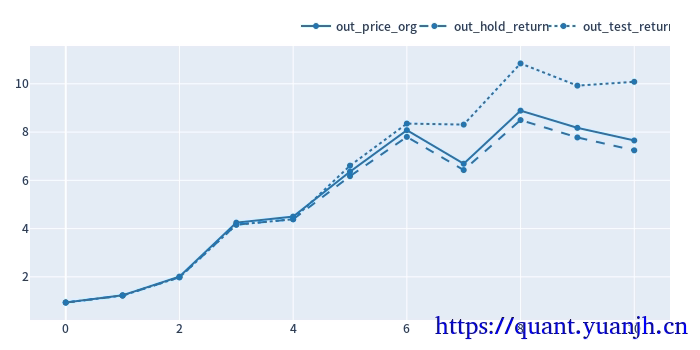
可见,在上次降低技术指标的预热时间优化的基础上,整体收益进一步提升。改进后的策略避免了参数过拟合,挺高了鲁棒性,带来了收益改善。
26,计算正确性验证(略)
a,准备校验数据,数据展示
b,行情->指标 计算正确
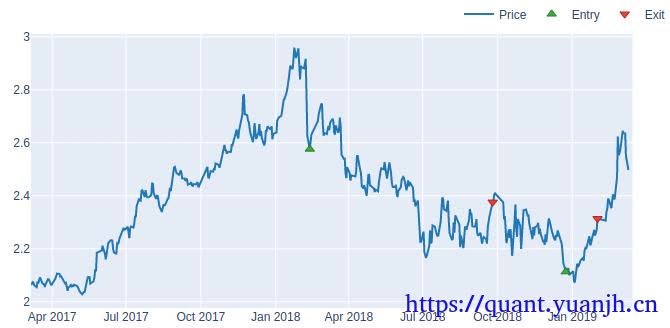
c,指标->信号 计算正确
d,信号->交易 计算正确